Server Design and Implementation
Table of Contents
TODO: Explain about why we choose Racer as reasoner. See OWLlink API
1. PHP Back-End
The figure fig:php-back-end-over-des shows the overall design about the PHP back-end structure representing the client on one side and the server on the other. Other modules and services can be added as needed providing a PHP script and associating it to an URL as a point of entrance where the HTTP request can be sended.
The objective is to present to the client some services that can be used standalone for some reasons: for testing while developing, for unit testing (see section sec:php-unit-testing), and for provide Web pages with stand-alone results without the whole interface working on it.
The user interface can use AJAX techniques to make HTTP requests when it needs any information from the server, for example: OWLlink or Descriptive Logic translations, one or all queries results by the Query Module, etc. The server can answer XML or JSON formated pages or a part of HTML depending on the interface needs.
2. Multiple User Sessions
The system should support multiple users using the reasoner and working on the user interface creating their own onthology designs. Thus, the server should track each users graphic model and translations and provide a reasoner instance for each current user.
For solving this matter the system can set a web browser cookie with a unique identifier (similar to the one created by the uuidgen terminal program 1) following this simple algorithm:
- If the user has a unique identifier (UUID) then
- Update the ``last usage'' date and time on its configuration file.
- If the user hasn't a UUID then
- Generate a UUID and store it on a configuration file with the current date and time.
- Send a Web browser cookie to the client with the recently generated UUID.
At some point, a PHP scripts executed each time a page is requested or a Cron job 2 should check if any UUID has a ``last usage'' date with a difference of more than a day according to the current date the server has, and if so, delete all the associated files with that user freing all the unnecesary information that hasn't being used so far.
If OWLlink, JSON or any other graphic model representation and any reasoner results need to be stored at the server, it should be identified with the UUID associated to the user creator as a prefix of the file name or as a field on the database.
Using Racer as a reasoner, it can only listen to one port unless the in-file and out-file parameters is provided as parameters in the command line, in such case it will create an instance of the programa and process the OWLlink or DIG in-file and return the results at the out-file. This avoids creating a lot of running instances waiting for instructions at differents ports on the server computer.
However, we should limit the number of connected users and queries they can do in parallel so no more that a given amount of Racer instances is running at the same time ensuring the server resources and safety.
2.1. PHP Web Creation
2.2. Translation Between JSON and OWL/OWLlink
There are more than one possible Descriptive Logic representation from an UML or simmilar model diagram, so we have to foresee the possibility of creating more than one translation algorithm with maybe some of them with different complexity.
For now, we'll work only with one translation technique according to DBLP:journals/ai/BerardiCG05. Otherwise, we'll provide support for implementing future translations techniques using the following design showed on figure fig:trans-mod-des.
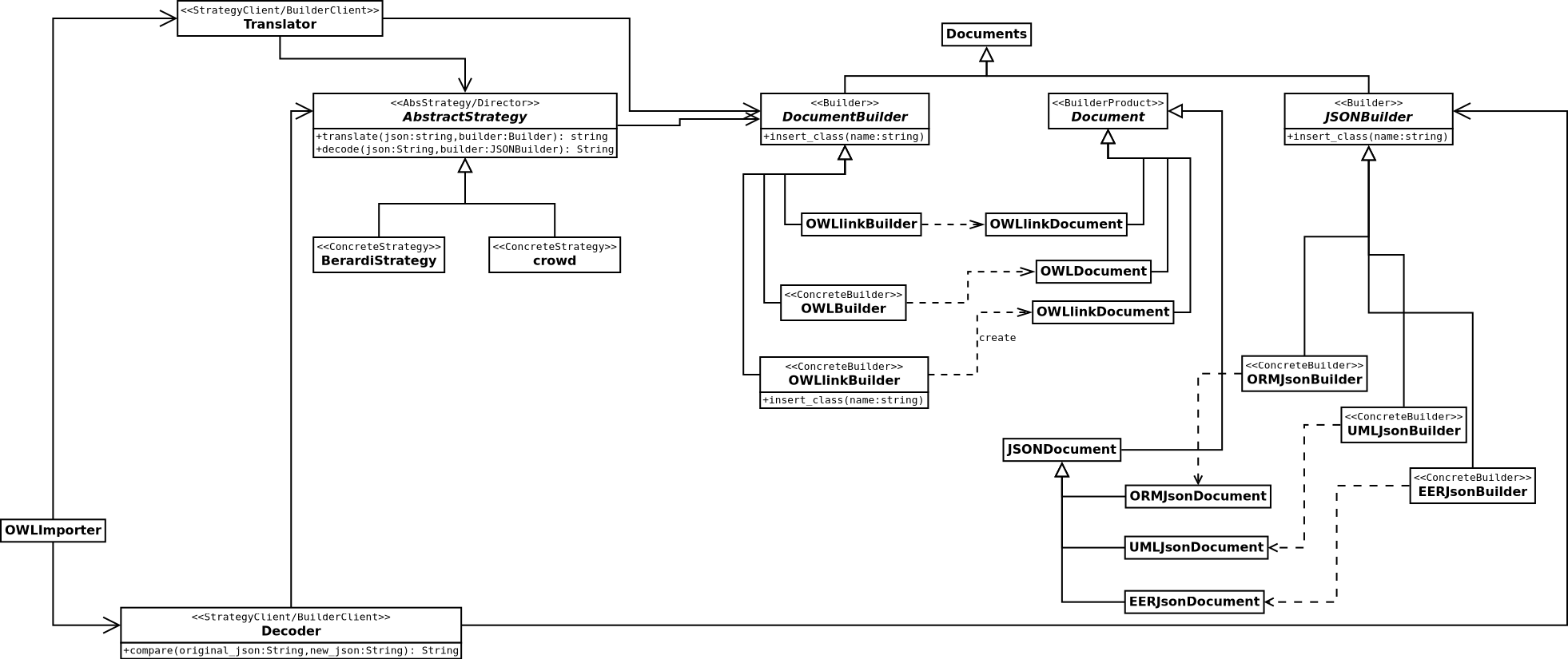
Figure 1: Translation module design.
TODO: Check if this is needed:
A Builder is needed to control the propper generation of the DL representation of the user's diagram into the different supported formats. OWL itself has various representations like XML, functional, Turtle, etc. and also, we may want to show to the user a Descriptive Logic symbolic representation.
The AbstractStrategy encapsulates the common behaviour inside its methods of any concrete strategy given. Creating a new subclass will give support for a new way of translating a model diagram into a Descriptive Logic representation.
3. Query Generator
We need to generate lots of queries for the reasoner about the satisfiability of the ontology design, so we create a module for solving such problem. The design is showed at figure fig:query-generator-design, and as its explain, a QueriesGenerator class has methods for adding all the queries in a format depending on the given builder.
As you can see, the QueriesGenerator instances doesn't need to know the format of the output, it just send all the Builder messages to do that. Even though, it works as the AbstractStrategy class depicted on figure fig:trans-mod-des, it manage the Builder as a Director giving instructions about what to insert into the Document product.
A Translator instance is necessary for creating the Builder subclass instance, initializing the product through it, and for giving the responsability to the AbstractStrategy subclass instance for adding the model representation and the QueriesGenerator instance for inserting the queries.
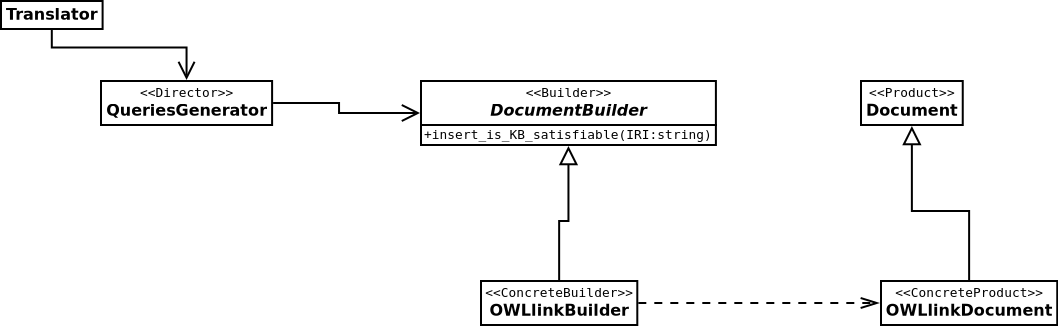
Figure 2: Queries generator UML class diagram.
4. Connection Between Racer and Back-End
We create a class called Runner with the objective to abstract the connection to the reasoner. It simple has the run(document : Document) method and it passed to the given Connector class.
The figure fig:runner-design has two parts, the abstraction part represented as the Runner class, and the implementation part by the Connector abstract class and subclass.
This design was choiced for giving the possibility to expand the software in a near future adding the feature for the user to select one reasoner for process the model onthology given. A connector subclass must be created for each new type of reasoner, for that reason we have a RacerConnector class, and must implements messages that has to send and recieve the information to the reasoner.
Also, if sessions are needed, Runner instances can have an association with a Session class wich will solve the matter of identifying the user. See the section sec:sessions for more information about the user sessions management.
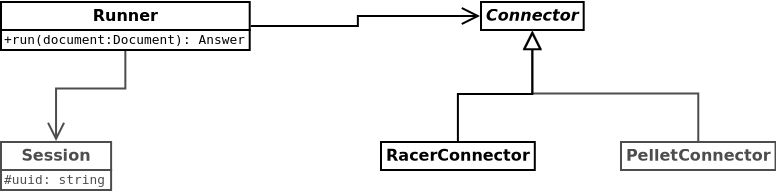
Figure 3: The connection design between the reasoner and the PHP backend.
5. Reasoner's Answer Processing
After the reasoner process the model given by the user, the system has to process its answer, generate the JSON file needed by the interface and send it as an HTTP response.
The answer processing depends on what kind of format the reasoner supports. Racer, for example support DIG and OWLlink, so we have to keep in mind that both formats could be supported in the implementation part.
At figure fig:answer-design we show the design for implementing the answer analizer. We simply create an abstract AnswerAnalizer class with the purpose to unify the interface and abstract the messages the client can use, but we leave for its subclass the implementation of such methods according to the format the reasoner outputs.
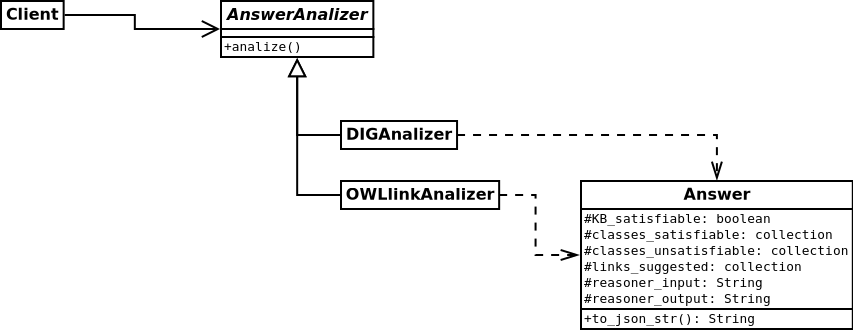
Figure 4: The answer processing UML class diagram.
The Answer instances are created and filled with information about the input and output of the reasoner and all the information needed by the interface that are of interest by the user.
5.1. OWLlink Parsing and Answer Generating Process
In particular, OWLlink has defined per each request sended the proper answer the reasoner must give. So, we have to compare one request tag with its counterpart in the answer.
An example is given at the figures fig:owllink-request-answer and fig:owllink-response-answer, let us understand this point. Also, for an initial development we can filter sometags related to the creation and release of the knowledge base, all the <tell> tags regarding to the onthology model representation and its corresponding answers.
<?xml version="1.0" encoding="UTF-8"?> <RequestMessage xmlns="http://www.owllink.org/owllink#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.owllink.org/owllink# http://www.owllink.org/owllink-20091116.xsd"> <CreateKB kb="http://localhost/kb1" /> <Tell kb="http://localhost/kb1"> <owl:SubClassOf> <owl:Class IRI="Person" /> <owl:Class abbreviatedIRI="owl:Thing" /> </owl:SubClassOf> </Tell> <IsKBSatisfiable kb="http://localhost/kb1" /> <IsClassSatisfiable kb="http://localhost/kb1"> <owl:Class IRI="Person" /> </IsClassSatisfiable> <ReleaseKB kb="http://localhost/kb1" /> </RequestMessage>
<?xml version="1.0" encoding="UTF-8"?> <ResponseMessage xmlns="http://www.owllink.org/owllink#" xmlns:owl="http://www.w3.org/2002/07/owl#"> <KB kb="http://localhost/kb1"/> <OK/> <BooleanResponse result="true"/> <BooleanResponse result="true"/> <OK/> </ResponseMessage>
6. Server API
The server provides reasoning and formalization services, along with user options like save and load models.
In the following sections we explain the design and implementation of the server part of crowd.
6.1. HTTP API
The Javascript interface needs some URLs ``entry points'' to do GET and POST request for recieve information. The AJAX technique consist on doing a background HTTP request to the server to retrieve some part of information to later process it if needed and display in one or more parts of the HTML documetns (usually the response is inserted into one or more <div>'s tags).
| URL Suffix | HTTP Request | Arguments | Purpose |
|---|---|---|---|
/api/translator/calvanesse.php |
POST | json=JSON STRING |
Translate using the Calvanesse TODO: cite calvansse papper!} method a JSON diagram representation into another format (i.e. OWLlink, XML OWL, etc.). |
/api/querying/satisfiable.php |
POST | json=JSON STRING |
Check if a JSON model representation and all its classes are satisfiable. Translation are done via the Calvanesse method. See sec:answers for more information about the JSON answer. |
/model_editor.php |
GET | The onthology model editor. | |
/index.php |
GET | Main web page. |
For doing so, we need to determine what is the server API the interface can use. The table tab:url-purpose is a list of URL suffixs and its purpose:
7. API and Directory Structure
In section HTTP API we explain that we need some URLs suffix predefined as entry points for making Ajax requests to retrieve information from the server when the user needs it after the web page is loaded.
For implementing this, we create a directory structure depicted at Figure fig:direc-struct that can follows the suffixs explained on Table tab:url-purpose. Each directory in the structure has its purpose conventionally determined for arranging the web system's files.
/wicom/- Here resides all the application classes definition. No HTTP request will generate any useful output. Subdirectories represents PHP namespaces.
/api/- API directory structure is defined here. HTTP requests will recieve useful output in JSON, XML or HTML parts.
/api/querying/- Queries to check the user model representation can be requested using these PHP scripts.
/api/translate/- Different user model representations and
methods can be translated through this point, a JSON can be
translated into OWLlink format by an HTTP request into one of
this scripts.
Each strategy has its own PHP file.
/api/translate/berardi.php- The Berardi proposed strategy.
/api/translate/crowd.php- The crowd experimental proposed strategy.
/css/ /imgs/ /js/- Assets needed by the web page: Stylesheets CSS sources codes, images and Javascript sources. Javascript are generated by the CoffeeScript compilation, except those that are inside the libs directory.
/js/libs/- Important Javascript libraries obtained by external sources like JQuery, Backbone, Joint, etc.
/coffee/- CoffeeScripts sources. These files will be compiled to Javascript and stored at
/js/directory. /common/- Common PHP functions. See section Common Functions for more information.
/config/- Configuration files.
7.1. Translation Parameters
The translation or formalization API recieves a POST request, the parameters are as follows:
- format
- A string representing the output format. For example:
"owl", "html", etc. - json
- A string with the model JSON representation.
The URL must point to the strategy PHP script.
The ServerConnection class has the request method implemented as
follow:
# Send to the server a translation Request. # # @param json {string} # @param strategy {String} "berardi", "crowd" or other strategy. # Remember that a strategy cannot be applied to other visual languages. # @param format {string} "owllink", "html" or any supported # translation format by the server. # @param callback_function A function to use as a callback when # the response is recieved. request_translation: (json, format, strategy, callback_function) -> url = @urlprefix + "api/translate/" + strategy + ".php" console.log "Requesting at " + url $.ajax type: "POST", url: url, data: "format" : format, "json" : json, success: callback_function error: @error_callback
8. Common Functions
We explains some functions available for saving code while programming PHP or CoffeeScript scripts.
8.1. Import Functions
The load() can load a module relative to the current file in static context.
When an HTTP is requested on an URL, when executing the PHP script associated to it, the current system path is the real one matching the virtual path. When requiring more modules via require or require_once PHP statements, all those will have the same current system path.
An issue appears when we want to require more dependence modules by the use of relatives path, because these must be modified to adapt to differents URLs and its diferents current real paths associated.
For example, on http://localhost/folderA/index.php the current path when executing index.php is the real path matching folderA virtual one, say ./proyect/folderA/index.php.
If this index.php requires the file ./proyect/folderA/folderB/require1.php , require1.php is a module that uses the folderA path as current directory, not folderB, and it may require something from other folder like ./proyect/folderA/folderC/require2.php so, it will have:
require_once '../folderC/require2.php';
This won't work… Because the current directory is the one matching the HTTP request virtual folder: ./proyect/folderA/.
This gets worse when require1.php is required by other PHP web page from other folder: If an HTTP request the http://localhost/index2.php and this index2.php requires ./project/folderA/folderB/require1.php, but require1.php wants the file on ../folderC/require2.php, wich will points to ./proyect/../folderC/require2.php giving up with an error.
A mechanism that concatenates relative paths can solve this problem:
- When
./project/folderA/index.phpexecutesload("require1.php", "folderB/")the current path should change to:./folderB/.- When
require1.phpexecutesload("require2.php", "../folderC/")the current path should change to:./folderB/../folderC/- When
require2.phpfinish, the current path should be restored to:./folderB/deleting whatrequire1.phpstored when loading this file.
- When
- When
- When
require1.phpfinish, the current path should be restored to :./deleting whatindex.phpstored when loading this file.
So, we use the load() function, and only the starting PHP scripts (i.e. API entry points) use the "requires" statements for loading the common.php file.
9. Runner and Reasoner Connectors
9.1. Problems We Faced
Racer 2.0 works as a standalone application and open some ports for recieving HTTP and/or TCP-only connections. It support DIG and OWLlink protocols for sending and recieving information and querying the ontology it store.
For sending our diagram and querying it satisfiability we have to send a HTTP POST request with the information at OWLlink format to the Racer.
According to the Racer example Web page,3 executing the following Curl command on the terminal while the razoner is running on the backgroun we should communicate with it and receive a correct answer: racer-example-page
curl -0 -d@owllink-example-Prefix-request-20091023.xml http://localhost:8080
The owllink-example-Prefix-request-20091023.xml file can be downloaded from the same Github repository where the examples resides. We tried and it did work as expected answering the OK tags indicating that the ontology has been loaded as it should.
9.2. Problem with Racer host and ports
The problem we faced first is connecting our PHP back-end with Racer. Racer has no means of configuration for setting the host properly, the only possibility is to use it as localhost or modify the internal code; the port is configurable via parameters and also the usage of the OWLlink protocol.
The command line used for starting racer on port 8080 in localhost is this:
./Racer -- -protocol OWLlink
TODO: Check if the original Racer start at localhost.}
We consider the usage of Racer on a different machine, then we have to provide a mean for changing its host IP and a way to connect using a PHP library or a console command executed by PHP.
TODO: Write about other Racer parameters for executing with an input and output file, ¿does it works as standalone application without opening a port?}
9.2.1. Apache Reverse Proxy
We consider the possibility to use an Apache HTTP server and use it as a reverse proxy, this will allow to use the host IP we want fowarding any HTTP request to the localhost process running at a predefined port.
We tried to configure Apache using the fragment of file on figure apache config, and then we run Racer as usually. We already know that executing a given Curl command directly to the Racer HTTP port should answer correctly, so we expect that given the same command to the Apache HTTP port should forward to the Racer port and thus should answer the same.
There are some configurations values relating to the host and port that resides in the main file of the Apache configuration, basically they are the default value and can be setted to our needs.
The following is the fragment of code that can be added to the configuration files to create a reverse proxy, i.e. order the Apache process to forward any HTTP request to the localhost IP (in this case 127.0.1.1) at port 8080.
<VirtualHost *:*>
ProxyPreserveHost On
# Servers to proxy the connection, or;
# List of application servers:
# Usage:
# ProxyPass / http://[IP Addr.]:[port]/
# ProxyPassReverse / http://[IP Addr.]:[port]/
# Example:
ProxyPass / http://127.0.1.1:8080/
ProxyPassReverse / http://127.0.1.1:8080/
ServerName localhost
</VirtualHost>
9.3. Ports and Localhost
PHP can connect using a Localhost TCP/UDP connection using the CURL command or library. We tried both possibilities and they didn't work properly:
9.3.1. CURL Command
Using the exec() PHP function can execute a CURL command. CURL creates the connections and send the information to Racer, but the answer recieved is not passed to PHP for some reason we don't know.
The code on figure code curl command can be used to recreate the scenario we tried and failed.
TODO: add the exec() code we used.
9.3.2. Using CURL Library
We tried to use the PHP Curl library to create the connection and recieve the razoner information. The HTTP POST request is sended but not properly as a simple HTML form, instead is sended as a multipart MIME that is not supported by Race.
We used the code on figure code curl library with different configuration listed below:
<?php // $curl_command = "curl -0 --crlf -d@owllink-example-LoadOntologies-request-20091116.xml http://127.0.0.1:8080"; $url = "http://127.0.0.1:8080"; $archivo = "owllink-example-LoadOntologies-request-20091116.xml"; ?> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html> <head> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> <title>Prueba</title> </head> <body> <h1>Prueba</h1> <?php $res = curl_init($url); $cfile = new CURLFile($archivo); $data = array('file' => $cfile); // curl_setopt($res, CURLOPT_HEADER, 0); curl_setopt($res, CURLOPT_POST, 1); curl_setopt($res, CURLOPT_POSTFIELDS, $cfile); curl_setopt($res, CURLOPT_SAFE_UPLOAD, false); // requerido a partir de PHP 5.6.0 curl_setopt($res, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_0); ?> <pre class="xml-output"> <?php curl_exec($res); curl_close($res); ?> </pre> </body> </html>
TODO: List the combinations we used to test the Curl Library}
9.3.3. Solution
For resolving this matter, we agreed to not to use TCP nor HTTP connections, instead we give to the reasoner the onthology model and the queries needed using a unique file in OWLlink format through argument in the command line.
PHP can execute external programs like in a terminal using the exec() function4, and the results is returned as a string or as an array if a variable is given as argument.
Racer can be executed using the following command for processing the file input-file.owllink and its results is returned at the standard output:
./Racer -- -owllink input-file.owllink
- Advantages and Disadvantages
Despite that this solution execute the command and recieve the answer, it has some disadvantages:
- The OWLlink file has to be generated with its model representation and all the queries each time the user wants to process the file through the reasoner.
- We cannot access the Racer process for debugging purposes, because it will finish as soon as the OWLlink file is processed. Instead, if we use HTTP connections, the process will remain active with all the onthology model in the RAM until sending the corresponding termination signal.
However, these are the advantages:
- The process won't remain active, so memory and CPU resources will be available for another task.
- Implementing different user sessions will be more easier in the future, because a new process can be created for each user resulting in separated Racer environments.
- Recreating the OWLlink file is much easier than checking for its differences for adding the user modifications since the last reasoner processing.
10. Testing with PHP Unit
TODO: Explain how testings has to be created for PHP functions.}
 1
1
TODO: Write about PHP Unit Testing and how to use it and how was created}
Footnotes:
See http://man7.org/linux/man-pages/man1/uuidgen.1.html (visited on march 03 of 2016) for more information about this command
See http://man7.org/linux/man-pages/man5/crontab.5.html (visited on march, 03 of 2016)
See https://github.com/ha-mo-we/Racer/tree/master/examples/owllink (visited on march, 03 of 2016)
For more information about the command, visist the PHP manual page at http://php.net/manual/en/function.exec.php.