R Practice 1
1 MASS library
The MASS package can be installed by using the command install.package('MASS'). It provides with the survey dataset.
To load the library and look at some rows of the survey dataset, the following commands can be used.
library(MASS)
survey
head(survey, 4)
Sex field has two levels. It is usually called factor when the variable is independent. A "treatement" is a possible combination on independent variables. Sex and Class with F/M and A/B values.
For more information about the dataset, use help(survey) instruction.
1.1 Age Mean
The following code calculate the mean value from the data on the Age column.
mean(survey$Age)
1.2 Levels
The next snippet shows the column's levels (the values founded).
levels(survey$Sex)
1.3 Plot
Plotting in R is achieved by the plot function. It will select the proper graphics style to use. There are more specific functions like barplot, boxplot, etc.
In the next example, plot will plot the Sex as X axis and the writing hand W.Hnd as Y axis.
plot(survey$Sex, survey$W.Hnd)
1.3.1 Labels
plot has got several parameters to customize the appearance of the graphic. For example, for changing the labels that appears on the title, the X axis and the Y axis. Also, it is possible to change the colour of each column.
plot(survey$Sex, main="Cantidad por género", xlab="genero", ylab="frecuencia", col=c("green", "yellow"))
1.4 Correlate without plotting
The cor.test function can be used to test for correlation between two columns. It support the three most common methods: Pearson's, Kendall's and Spearman's.
Usually, a cor value nearer to 1 means it is very related. In the following instance, Pearson's is used beacuse of the nominal data type of the columns.
res <- cor.test(survey$Wr.Hnd, survey$NW.Hnd)
print(res)
The results is stored at the res variable. To consult the correlated estimation, use the $ operand.
res$estimate
1.5 More Examples
1.5.1 Mean
The mean calculation is simple. Remember that mean is sensible to the extreme values. The following example shows how to create a vector with some values and calculate its mean.
r <- c(6, 7, 8, 7, 6)
mean(r)
Another instance, where the mean is calculated with extreme values.
t <-c(10, 10, 10, 2, 2)
mean(t)
If the standard deviation (SD) is near to zero, then is more aproximate to use the mean. In other words, the mean is more significative when the SD is nearest to zero. The following calculate the standard deviation using the sd() function.
print(sd(r)) print(sd(t))
1.5.2 Median
Geometric median is calculated by using the nstat package.
1.5.3 Mode
The mode can be calculated by using the modes or the frequency package.
The following snippet create a table which counts the amount of repetitions of each number in the vector.
v <- c(1, 1, 1, 2, 2, 3, 4, 4, 5, 6, 6, 7) example <- table(v) example
Using the modes package gives the following results.
library(modes)
modes(v)
- Using Formulae
The mode can be calculated by using formulae. For each item,
examplehas got the amout of repetitions on the vector.Suppossing that
 is the amount of repetitions of the one item, and
is the amount of repetitions of the one item, and 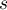 the length of the vector. The following formulae shows the persentage of appearances for the item:
the length of the vector. The following formulae shows the persentage of appearances for the item: 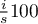
R can calculate the same formulae for each row simply replacing the item with the table name.
c <- (example/length(v))* 100 cThe following code creates a dataframe which displays the frequency, the calculated relative frequency for each element.
req <- data.frame(freq=example, relative_freq=c) req
1.5.4 Summary
The summary function provides some information about a dataframe and its columns.
summary(survey)
Female:118 Min. :13.00 Min. :12.50 Left : 18 L on R : 99 Min. : 35.00 Left : 39 Freq:115 Heavy: 11 Min. :150.0 Imperial: 68 Min. :16.75 Male :118 1st Qu.:17.50 1st Qu.:17.50 Right:218 Neither: 18 1st Qu.: 66.00 Neither: 50 None: 24 Never:189 1st Qu.:165.0 Metric :141 1st Qu.:17.67 NA's : 1 Median :18.50 Median :18.50 NA's : 1 R on L :120 Median : 72.50 Right :147 Some: 98 Occas: 19 Median :171.0 NA's : 28 Median :18.58 nil Mean :18.67 Mean :18.58 nil nil Mean : 74.15 NA's : 1 nil Regul: 17 Mean :172.4 nil Mean :20.37 nil 3rd Qu.:19.80 3rd Qu.:19.73 nil nil 3rd Qu.: 80.00 nil nil NA's : 1 3rd Qu.:180.0 nil 3rd Qu.:20.17 nil Max. :23.20 Max. :23.50 nil nil Max. :104.00 nil nil nil Max. :200.0 nil Max. :73.00 nil NA's :1 NA's :1 nil nil NA's :45 nil nil nil NA's :28 nil nil
Be carefull when the N/A value is present on one of the column. For example, the pulse column has NA values and can change the results of some functions.
print(min(survey$Age)) print(max(survey$Age)) print(min(survey$Pulse)) print(min(survey$Pulse, na.rm=T))
The min function returns N/A if it is not ignored. Using na.rm=TRUE as parameter make min to ignore them.
2 Aplication of tests
IV: Independent variable DV: Dependent variable
| IV | DV | |
|---|---|---|
| Variable factor 2 levels | Likert | Test no param Mann-Whitney |
| Factor + 2 levels | Likert | Kruskel-Wallis |
3 License of This Work
This work is licensed under the Creative Commons Attribution-NoDerivatives 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nd/4.0/.

R Practice 1 by Gimenez Christian is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.